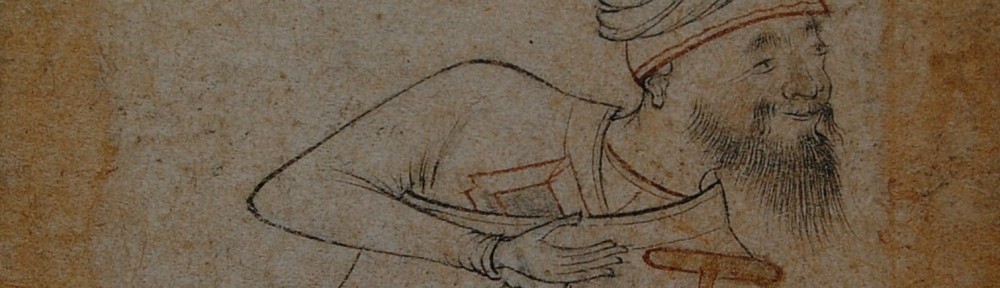
William Ouseley’s label for an undated miscellany, pasted unto the front board’s inside of MS pers. Bodl. Ouseley 28, h = 20.5 cm
Gore Ouseley’s undated exlibris, from a fly leaf in one of his copies of Saʿdī’s Kullīyāt, MS pers. Bodl. Ouseley Add. 39, dated 856 H./ 1452, h = 21 cm
In March 2022 I was awarded a Bahari Visiting Fellowship in the Persian Arts of the Book at the Bodleian Libraries, which I will hold from 2 May to 1 August 2023. In support of my Bahari fellowship project I received a minor grant from the Oxford Bibliographical Society (OBS) and a grant form the Persian Heritage Foundation (PHF), as well as a non-stipendary Visiting Fellowship at St. Edmund Hall for Michaelmas Term 2022. I owe many thanks to Jake Benson, Susan Boynton, Richard Bulliet, Manuela Ceballos, Elizabeth Evenden-Kenyon, Lalla Rookh Grimes, Henrike Lähnemann, and Marina Rustow for their support of this project. Here follows the report which on 27 February 2023 I submitted to the OBS.
My Bahari fellowship project draws on the Bodleian’s Persian manuscripts of the Anglo-Irish orientalists Sir William Ouseley (1767-1842) and his brother Sir Gore Ouseley, bt (1770-1844). William pursued between 1788 and 1794 a military career with the Royal Dragoons, and then focused on Persian studies. In contrast, Gore lived from 1787 until 1805 as an independent business man in India. He led from 1810 until 1815 – with William as his private secretary – a British diplomatic mission to Tehran and St. Petersburg to assist with the Golestan Treaty negotiations between Iran and Russia. Although the brothers today are celebrated for their bibliophilic codices (e.g., Shāhnāma MSS Bodl. Ouseley Add. 176 and Ouseley 369), most Ouseley manuscripts are devoid of any illumination or figurative painting. The brothers bought Persian texts to study Persian literature, and this lifelong passion is reflected in their publications: William’s Persian Miscellanies (1795, ESTC T154204) is the first English language essay about Persian paleography, and Gore’s Biographical Notices of Persian Poets (Oriental Translation Fund, 1846) is a literary history, compiled from translated Persian sources. When between 1843 and 1859 the Bodleian acquired, through different channels, about 1,000 Ouseley manuscripts, they became an influential resource for Persian studies in Britain. The perhaps most famous example is William’s copy (Bodl. Ouseley 140, dated 865 H./1460) of the divan of ʿUmar Khayyām (1048-1131), which served as a source text for Edward FitzGerald’s Rubáiyát (1st ed. 1859), thereby making the Saljuq mathematician one of the best-known Persian poets in English translation.
The Bodleian’s Ouseley collection is a representative sample for the international trade with Persian books during the Georgian era. After the 1757 battle of Palashi (Plassey) in West Bengal, the expansion of the East India Company’s economic influence was accompanied by an increasing British demand for Persian literature, as well as for Arabic, Urdu, Hindi, or Sanskrit literature. In the book trade in India and Iran this British demand created a secondary, antiquarian market which catered to foreigners. As local and foreign buyers possessed different levels of both familiarity with the canons of oriental literature and expertise in the oriental arts of the book, damaged books which sophisticated local patrons would reject could still be sold to inexperienced foreign customers. These British purchases were manuscripts, since commercial Muslim workshops only transitioned from manuscript copying to printing from the 1820s onwards.
Against this backdrop I argue that the materiality of the Ouseley manuscripts, in particular codicological evidence of repairs and recycling, reflects a stratified book trade in India and Iran. Books are three-dimensional mobile objects with a limited lifespan, because wear-and-tear will eventually destroy every book, however precious. But a damaged book may be preserved, if its presumed market value justifies repairs or recycling as economically sensible interventions. The damaged book’s intended reuse will, in a second step, determine the application of repair or recycling strategies. While these interventions may, or may not, alter a book’s written content, they often destroy copy-specific evidence, such as paratexts which could have allowed for a historical contextualization of its written content’s diffusion.
The overarching goal of my Bahari fellowship project is to highlight the agency of Indian and Iranian dealers at the intersection between book production and the international antiquarian manuscript trade by demonstrating the impact of their material interventions on the textual transmission of Persian literary sources. The codicological analysis reveals fragmentation and reconstruction as complementary strategies with crucial significance to editorial criticism: e.g., Bodl. Ouseley 131 and Ouseley 141, as well as Ouseley 140 with ʿUmar Khayyām’s divan, are fragments of a lost poetic anthology from Turkmen Shiraz, while Bodl. Elliot 5 is a ghost as the composite codex, built up from recycled Akbarnāma fragments, offers an incomplete unique text.
On 24 November 2014, Steve Tamari (Southern Illinois University Edwardsville) had convened at the annual meeting of the Middle East Studies Association (MESA) in Washington, DC round table [R3670]: “Is There a Need for a New Primary Source Reader of Pre-Modern Civilizations?” Below follows the précis which I had submitted as one the round table participants. I was the only participant to argue for a digital Open-Access textbook.
I am proposing to develop a source book of Middle East history between 600 and 1800 CE as an Open-Access (OA) digital database. In the US the majority of today’s undergraduates are digital natives. They may prefer printed books for some of their reading, but most of them will have grown up with digital devices and social media. Taken together with the rise of Massive Open Online Courses (MOOCs) and Digital Humanities (DH) initiatives of grant giving organization, it seems thus possible to launch this new textbook on the Internet as an OA database. Although its creation and medium-term maintenance pose their own technical and financial challenges, such an OA database would be accessible to students outside the US and the creation of its contents could be organized as a collaborative transnational project, whose participants will have to decide which of the available platforms (e.g., Wiki, WordPress, Omeka, FlickR) would be most appropriate and cost-efficient for the project.
Organized as a database a source book would offer the opportunity to cover in a more adequate fashion the complexities of premodern Muslim societies. A printed book’s space limitations make it almost impossible to challenge the traditional views of Middle East history, whether they are Sunni, Shiʿi, Arab, Iranian, or Turkish, and to expand introductory courses on Middle East history, politics and economics so that culture and the arts and sciences will also be covered. In contrast, the storage capacities of a digital database would make it possible to accommodate the full diversity of the preserved sources, such as documents pertaining to Zoroastrians, Jews, and Christians as well as Kharijis, Zaydis, Ismailis, Alevis, Babis, Bahais, and Ahmadis. Moreover, only an OA digital database can take full advantage of the OA depositories of digitized manuscripts and printed books, art objects, audio files, or coins already available on the Internet (e.g., Women’s World in Qajar Iran, Eastern Art Online, Refaiya Library).
To develop this textbook as an OA resource would allow scholars to gain a modest degree of independence from the pressures of commercial academic publishers, while being mindful of the steadily increasing costs of a US college degree. Since textbooks are an important source of revenue, publishers are vigorously defending their copyright claims whenever they are negotiating with colleges and universities the uses of copyrighted material in the classroom. Moreover, the database’s diverse contents will help instructors to regularly vary reading assignments.
Amended, 6 March 2022
PS 1 – In October 2021, I posted this 2014 précis here on my blog, as I was reviewing the resource collections of the Invisible East programme at the University of Oxford in preparation for an ultimately unsuccessful job interview for a fourteen-month position as research associate. Arezou Azad (University of Oxford) directs the progaramme. Its most general goal is to initiate a paradigm shift in research about the history of Iran, Afghanistan and Central Asia between the eighth and the thirteenth century CE by highlighting the diversity of extant and accessible written sources in New Persian, Judeo-Persian, Arabic, Bactrian, Sogdian, Khotanese and Middle Persian. In order to affect this paradigm shift, Dr. Azad and her team are committed to the creation of an Open-Access digital corpus. This forthcoming collection of written witnesses is not mentioned in the posted project description, and so far few concrete details have been published, while the work is under way.
PS 2 – In 2021 two important articles about the digital sources of historical research – both digital surrogates and born-digital – were published in the American Historical Review (AHR): Itza A. Carbajal and Michelle Caswell, “Critical Digital Archives: A Review from Archival Studies,” AHR 126.3, pp. 1102-1120; https://academic.oup.com/ahr/article/126/3/1102/6421763; and Joseph L. Locke and Ben Wright, “History Can be Open Source: Democratic Dreams and the Rise of Digital History,” AHR 126.4, pp. 1485-1511; https://academic.oup.com/ahr/article/126/4/1485/6525105. Locke and Wright are tenured professors of American history who review the ethical and financial challenges that impact the capacity of digital humanists to create Open-Access teaching resources for digital history at the contemporary America neoliberal university. While the two men explicitly restrict their survey to the United States (p. 1486 n.3), their analysis of the tension between the desire for Open-Access pedagogical resources and the persistent challenges of how to properly recognize and fairly remunerate the indispensable – yet mostly invisible – labor of their creation is relevant to Digital Humanities projects in general. In contrast, Carbajal and Caswell are archival practitioners who are caring for archives of Latin American and South-Asian American minorities, respectively, while being a doctoral student and a tenured professor of information studies (pp. 1104-1105). Their article surveys the archival practices that accompany the current flowering of so-called digital archives projects. The two women identify seven key themes in the theory and practice of digital records management in archival studies in order to increase historians’ awareness of the complexities that deeply affect the digitally available sources of historical research.
As a historian of pre-modern Muslim societies, I am reading not only the written sources of the Islamic civilization but also the materiality of the media through which these written sources were preserved. Their materiality comprises the writing surface itself – marble, slate, clay, papyrus, textiles, palm leaf, paper, bits and pixels – and its “packaging” (e.g., binding), as well as the visual arrangement of the text (i.e., mise-en-page) and its illumination and illustration.
In the eastern Mediterranean, parchment and papyrus were commonly used writing surfaces in late antiquity, when the codex had replaced the scroll as the dominant format of books. Islam emerged in the early seventh century on the Arabian Peninsula, and the earliest extant Islamic manuscripts in Arabic script are parchment codices and documents written on papyrus. Since the ninth century, paper has been the most important writing surface in Muslim-ruled societies
Paper-making technology entered the Islamic civilization as a Chinese invention. In Central Asia, around 700, Muslim governors were the first to use paper documents in their written administration of recently conquered territories. In the 750s the first paper mill was established in Abbasid Baghdad in Mesopotamia, the new capital of the Sunni caliphate which was going to dominate the Islamic East until the Mongol conquests of the thirteenth century. The Islamic adaptation of paper-making technology is considered an important factor for the intellectual and creative flourishing of the Arab-Islamic civilization between the late eighth and the eleventh century, since as a writing surface, paper was more durable than papyrus and less costly than parchment. These practical advantages of paper, taken together with its low-complexity manufacture and relative affordability, spurred the increased uses of literacy and writing in all aspects of life in Muslim-ruled communities in Eurasia and Africa.
It is against this backdrop that the topos of the abundance of books in medieval Muslim-ruled societies emerged. The wealth of premodern Islamic book cultures across Eurasia and Africa is usually contrasted with the scarcity of books in Christian Europe during the Middle Ages, on the one hand, and on the other hand, with the absence of printing technology from the commercial manufacture of books by Muslim workshops before the nineteenth century. Since the late 1970s, the topos of the abundance of books has given way to the celebration, if not fetishization, of Islamic manuscript culture as one of the most important achievements of the Islamic civilization.
In my lecture, I will investigate this topos of abundance, which is both triumphalist and defensive. The historical record of the premodern Islamic civilization is much more fragmentary than commonly acknowledged, because our own obsession with wealth and ownership loses sight of absences and gaps, loss and destruction. Despite our own daily experience of limited storage capacities so that we need to regularly discard old things in order to have space for new things (see “fast fashion”), we are reluctant to acknowledge that each book is also a utilitarian, commercial commodity. Nonetheless, I will argue that the practical advantages of paper make it feasible to replace damaged books with new copies. In the twenty-first century, paper, as the formerly dominant writing surface, competes with the bits and pixels of computer screens, because books, as media for written contents, are not defined by the materiality of their writing surface.
Madrid, Calle Albasanz 26-28 – 4 April 2017
Madrid, Calle Mayor/Plaza de la Villa – 15 April 2017
* Précis of my contribution to Paper Trails: Post-Industrial Histories, Technical Memories and Art Practices, a trans-disciplinary online seminar, organized by the Ecole de Design et Haute Ecole d’Art (EDHEA, Valais, Switzerland) and the Instituto Politécnico de Tomar (IPT, Tomar, Portugal), Fall 2021.
In 2021, after more than a decade of public acknowledgements of the growing inequality between the poor and the wealthy, the concepts of illegitimate and legitimate ownership of any particular culture, however intangible, have acquired visceral ethical implications in everyday life which transcend academic research on cultural appropriation in postcolonial studies and related fields. Ownership of a particular culture has been essentialized to protect at least the possession of our immaterial property, that is: intangible cultural heritage, against the absolute logic of market capitalism in the neoliberal age. Against this backdrop, any investigation of the border-crossing mobility of manuscripts in Arabic script raises the question how contemporary best practices for acquisition and collection management inform our interpretation of the available evidence whether past acquisitions were spoils of war, stolen goods, gift giving, or legitimate commercial transactions.
The question is particularly acute for manuscripts in Arabic script which are nowadays held in private collections and public memory institutions outside Muslim majority societies. The depth of the historical collections of manuscripts in Arabic script in the former imperial capitals of Paris, London, or Vienna is well known. Even regional European libraries hold small, though important Islamic collections, like those in Hamburg, Munich, and Bologna which were acquired as part of the private libraries of Albrecht Widmanstetter (1506–1557), Abraham Hinckelmann (1652–1695), and Luigi Marsili (1658-1730), respectively. At the same time, the border-crossing mobility of manuscripts in Arabic script also occurred within the Islamic lands, between South Asia and North Africa, between the Balkans and Central Asia. Their circulation across the Islamic lands forces scholars to search for codicological and literary evidence that the manuscripts themselves were moving, and not the artisans. Art historians vigorously debate whether certain Persian bibliophilic codices were – despite the Safavid style of their calligraphy, illumination, figurative paintings, and bindings – the work of Ottoman or Mughal workshops. In contrast, the circulation of manuscripts in Arabic script outside the Islamic lands has turned into the proverbial elephant in the room. In the early 1870s, when traveling in the Arab provinces of the Ottoman Empire, Ignaz Goldziher (1850–1921) bought for the just founded Hungarian Academy of Sciences in Budapest only printed books because the foreign demand for manuscripts – as Goldziher had learned from his Arab colleagues – had made them too expensive on the book markets in Damascus and Cairo. About a century later, Edward Said (1935–2003) presented in Orientalism the steady flow of manuscripts from the Islamic lands to Paris and London – the beginning of which he dated to about 1800 – as evidence for the indebtedness of modern European philology to this displaced Arab-Islamic treasure trove of knowledge.
The international trade with manuscripts in Arabic script can be documented from the sixteenth century onwards with the historical holdings which have survived – against considerable odds – in contemporary collections in Europe and North America. I argue that the work of book dealers like Abraham Yahuda (1877–1951) has to be understood within this long tradition of highly educated middle men selling manuscripts in Arabic script to foreigners in order to make a living. However, at the current state of descriptive cataloguing, codicological evidence for the international book trade is often omitted from manuscript descriptions as research continues to focus on the manuscripts’ contents as well as on workshops, patrons, or owners. In other words, the agency of sellers and dealers has received much less attention. Taking advantage of the less charged research about commercial transactions with “western” books as hard-nosed, unsentimental business, it becomes possible to recognize the codicological evidence of the international trade with manuscripts in Arabic script and its impact on Middle Eastern and Islamic studies as practiced outside the Islamic lands since the Renaissance.
* Abstract of my contribution to the online symposium about A.S Yahuda and Islamic Manuscripts, originally scheduled for 1-3 June 2021 but now postponed to 2022 when it will be convened as an in-person event at Princeton University. The symposium is sponsored by Princeton University and the College of Charleston; for more information about the organizing committee, see the symposium’s website https://web.archive.org/save/https://yahuda.princeton.edu/symposium-2021/speakersandsponsors/.
In August 2020 Emma Hagström Molin organized a two-day ZOOM workshop about provenance with the support of the Centre for Integrated Research on Culture and Society (CIRCUS) of Uppsala University (Sweden). Her current research on the material conditions for historical research during the nineteenth century is funded by an international postdoctoral fellowship of the Swedish Research Council, and she had convened a diverse and lively group of presenters and listeners. As the ZOOM workshop was not open to the public, it does not have a website with detailed information about its program and presenters.
On the second day the workshop effectively closed with a question posed by Claes-Fredik Helgesson, the director of CIRCUS. Helgesson ruminated whether mapping could help with organizing the bits and pieces of our collective knowledge of the various aspects of provenance, thereby analyzing and elucidating how the concept’s meaning and its epistemological status in classification schemes has evolved in diachronic and synchronic perspectives, over time and across space. Helgesson’s use of the word “mapping” was intriguing. It made me wonder about the viability of a future Digital Humanities (DH) project which would employ visualization tools for constructing a history of the concept of provenance, while tracking changing practices of provenance research in a range of disciplines in the Humanities and the Sciences.
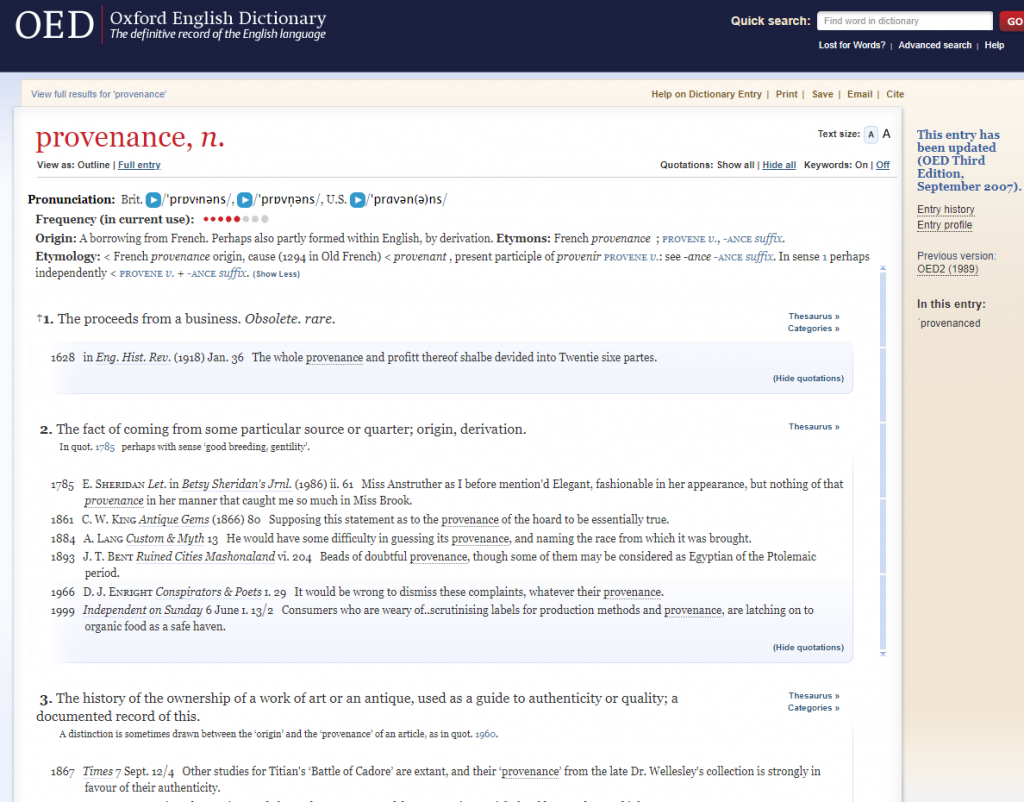
Hagström Molin had opened her introduction to the workshop with a reflection on the history and etymology of the word “provenance,” bringing into the discussion how Gail Feigenbaum and Inge Reist define the word in their introduction to Provenance: An Alternative History of Art (Los Angeles: Getty Research Institute, 2012, 1 and 4 n.1). Feigenbaum and Reist state that in the Oxford English Dictionary (OED) the first documented use of provenance occurred in 1785, when the word served as shorthand for “history of ownership,” with the extended meaning of “documented record.” Unfortunately, Feigenbaum and Reist do not identify date and format (that is, printed or digital) of the consulted OED version. More important, though, is their astute observation that “[o]n the face of it, we all know what provenance means” (p. 1). A short survey of recent English-language scholarship confirms that the word’s meaning is indeed perceived as being self-evident – which usually is a red flag that things are more complicated than we would like them to be. Nick Pearce and Jane C. Milosch open their introduction to Provenance and Collecting (London: Rowan & Littlefield, 2019) with this breezy statement: “The most basic definition of the word provenance is ‘place of origin’ from the French provenir, ‘to come from,’ and before this, the Latin provenire: pro, ‘forth’ and venire ‘come.’ Increasingly, the word has come to be closely associated with the history of creation and ownership of a specimen, artifact, or work of art” (p. xv). Unlike Feigenbaum and Reist, Pearce and Milosch do not provide a reference for these etymological and historical details, and yet they draw attention to the word and its meaning. Victoria Reid does not comment on the word itself in her entry on “Provenance” in Grove Art Online (Oxford: Oxford University Press, 2003, updated 2016, https://doi.org/10.1093/gao/9781884446054.article.T069868), and neither does David Pearson in his handbook about Provenance Research in Book History (2d ed., Oxford: Bodleian Library, 2019).
My own reading of the entry on provenance in the current version of the OED Online, which provides the text of the third revised edition of 2007, differs from that offered by Feigenbaum and Reist, but they may have consulted an earlier edition of the OED.
NB – The entry’s remainder is not shown as it merely provides more citations for the word’s third meaning.
The note on provenance’s origin includes a warning: “A borrowing from French. Perhaps also partly formed within English, by derivation.” The first identified meaning draws on a 1918 article for the citation of a 1628 source to conclude that in the early modern era the word provenance was used in business transactions to indicate “the source of profit.” This first meaning, though, is marked as rare and nowadays obsolete. As regards the documented use in 1785, highlighted by Feigenbaum and Reist, the citation is presented as evidence for the second meaning: “[t]he fact of coming from some particular source or quarter; origin, derivation.” But the OED editors add the disclaimer that the 1785 citation may represent a slightly different usage than that illustrated by the following citations for the nineteenth and twentieth century. The oldest given citation for the third meaning, which represents the word’s contemporary usage by art historians as contextualized by Feigenbaum and Reist, was published in 1860.
I draw three conclusions from this linguistic evidence. The first is that it offers a timely reminder about the importance of French as one the languages of medieval and early modern England. A word that looks like a borrowing from French does not automatically point to Franco-British contacts in the late eighteenth century. The second conclusion is that it directs attention to the close relation between provenance’s meaning in the seventeenth and eighteenth century. While the seventeenth-century meaning was narrow and precise, the eighteenth-century meaning had broadened and became more general. The third conclusion is that it presents the evolution of provenance’s meaning as metonymy, if its history is read backwards, from the present to the past: an object acquires value when authenticity is confirmed and owners are known, thereby becoming a source of profit.
Against this backdrop I offer the working hypothesis that the concept of provenance – defined as the chain of ownership, whether legal or illegal, through which a mobile or immobile object was transferred between people – is present in every society whose members can own private property and whose economy supports markets and a practice of individual collecting. While more comparative research would be necessary to identify the role of conspicuous consumption for practices of individual collecting, I hasten to add that I am not arguing that owning individual property is an anthropological constant. In order to facilitate a comparative approach based on a range of disciplines from the Humanities and the Sciences, I would suggest to employ a heuristics that draws on semiotics to distinguish between word (signifier), meaning (signified), and concept (referent). This heuristic strategy would allow for investigating changes and differences between languages, eras, and locations, thereby revealing developments over longer stretches of time. The concept of provenance is posited to be stable, but words and meanings change, be it in conjunction or be it separately. On the one hand, a word remains in use, but its meaning is new; an example would be looting. On the other hand, the meaning is retained, although it is now attached to a different word; e.g., we approve of national heritage but shun the common good. One of the possible outcomes of this heuristic approach could be a representation of the different aspects of the concept of provenance, for example, through three different maps visualizing words, meanings, and the changing relations between them.
In all literate societies, the vast majority of books are utilitarian commodities whose most important feature is their reproducibility, be it in the same medium (e.g., manuscript to manuscript) or be it in a new medium (e.g., manuscript to digital surrogate). The technology of writing allows for the manufacture of new copies, irrespective of a book’s format (that is: tablet, scroll, roll, codex, e-book), whenever it seems opportune or necessary to replace an old copy with a new copy. At the same time, books and their contents are continually destroyed in the course of natural disasters, warfare, censorship, deaccession, or wear and tear. Between these extreme poles of unlimited reproducibility and pending permanent disappearance, we can recognize the contours of two different book cultures: utilitarian books with texts for readers and rare or bibliophilic books regarded as valuable. But what we think about particular texts and artifacts changes over time, and thus books move back and forth between these two cultures.
In their introduction to Provenance: An Alternate History of Art (Los Angeles: Getty Research Institute, 2012), Gail Feigenbaum and Inge Reist conceive of provenance as “a kind of shadow social history of art” (p. 3). Books, though, are different from works of art – if we are disregarding livres d’artistes. While works of art nowadays require provenance records as documentation of legal ownership, David Pearson observes in the introduction to his handbook about Provenance Research in Book History (2d ed. Oxford: Bodleian Library, 2019) that the complete absence of any information about earlier owners is as common as the preservation of some details indicating a book’s social history (pp. 9–10).
It is against this backdrop that I will draw on selected holdings of Columbia University Libraries in order to explore how the officially available information about the provenance of manuscripts and printed books in Arabic script provides new insight into changing perceptions of their international trade and their value. The investigation of their provenance and sale cannot be separated from the interrogation of the legitimacy of their ownership, because their social history inside and outside Muslim communities is linked to contemporary debates about Orientalism and Islamophobia. I argue that the dual nature of books – they can be cultural heritage and run-of-the-mill cheap copies – necessitates a reflection about different concepts of individual and collective ownership vis-à-vis representations of power and historical responsibility.
Note1. With regard to the methodological challenge which is posed by the economic reality that books are commodities, and this economic reality comprises even rare luxury volumes which are manufactured to order for wealthy patrons or religious institutions, I find it useful to contrast the heritage value of mobile commodities such as old books to the heritage value of old buildings which can be neither replaced by a new copy nor picked up and whisked away; see Jaume Franquesa, “On Keeping and Selling: The Political Economy of Heritage Making in Contemporary Spain, Current Anthropology 54.3 (June 2013): 346-369; DOI: 10.1086/670620.
Note 2. While scholars investigate an artefact’s provenance when determining its authenticity or its legal owner, antiquarian book dealers explore the associations which form a book’s web of human relations in order to possibly enhance its emotional or intellectual value in the eyes of its customers. Three contemporary glossaries on book collecting, western codicology, and bookselling illustrate different perceptions of provenance vis-à-vis association, documenting that in the world of books provenance and association are complementary concepts.
John Carter and Nicolas Barker, ABC for Book Collectors, 8th ed. with corrections, Newcastle, Del.: Oak Knoll, 2006. 1t ed. in the UK, London: R. Hart-Davis, 1952.
Michelle P. Brown, Understanding Illuminated Manuscripts: A Guide to Technical Terms, London: BL, 1994.
Glossary on the website of the International League of Antiquarian Booksellers (ILAB), available at: https://ilab.org/glossary
* Abstract of my talk at the workshop about Provenance: Interdisciplinary Conversations, organized by Emma Hagström Molin at the Centre for Integrated Research on Culture and Society (Circus) of Uppsala University (Sweden). The ZOOM workshop will take place on 20-21 August 2020.
On 31 January 2019, my Marie Curie Fellowship ended after twenty-four months. The Horizon2020 rules for the MSCA Individual Fellowships stipulate that after sixty days the host institution and its Marie Curie Fellow have to submit a final report to the European Commission. This report comprises a public summary, eventually to be published on CORDIS (https://cordis.europa.eu/project/rcn/206308/factsheet/en), and a confidential technical account, the financial part of which is inaccessible to the fellow. The grant’s final installment will only be released to the host institution, if it is decided, on the basis of this final report, that the fellowship was successful. Below follows an advanced draft of the public summary, which is not yet structured in accordance with the public summary’s checklist. For the time being, scholars can apply for a Marie Curie Fellowship at any point of their career. In keeping with the terminological conventions of Horizon2020 and the MSCA, Marie Curie Fellows are called Experienced Researcher (ER), even if they are less than seven years after the receipt of their degree(cf. the NEH distinction between junior and senior scholars). However, a Marie Curie Fellow cannot be the Principal Investigator (PI) of her grant, since the fellowship is awarded to the host institution where her sponsor is responsible for the budget.
Making Books Talk: The Material Evidence of Manuscripts of the Kitāb al-shifāʾ by Qāḍī ʿIyāḍ for the Reception of an Andalusian Biography of the Prophet between 1100 and 1900
The project explored the transformation of an early twelfth-century Arabic treatise on Islamic dogma (Ar. ʿaqīda), which was written in the Islamic West, probably in the port city of Ceuta (Ar. Sabta), North Africa, into a work of pious literature that today is studied by Sunni Muslims all over the world. The Kitāb al-shifāʾ bi-taʿrīf huqūq al-Muṣṭafā (“The book of healing concerning the recognition of the true facts about the Chosen One”) was composed by ʿIyāḍ b. Mūsā al-Ḥāfiẓ Abū’l-Faḍl al-Yaḥṣubī al-Sabtī (1083–1149 CE), also known as Qāḍī ʿIyāḍ. Serving as a judge (Ar. qāḍī) in his hometown Ceuta between 1121 to 1147, as well as for less than a year, between 1135 and 1136, as a judge in Granada, Spain, Qāḍī ʿIyāḍ was a celebrated jurist of the Maliki school of law with a particular interest in historical accounts (Ar. ḥadīth “story, tradition”) about the prophet Muḥammad (d. 632).
Societal Relevance. The project’s publications provide concrete historical context for the current debates on religious diversity and Islamophobia in western societies. On the one hand, the Kitāb al-shifāʾ is associated with Iberia before 1500, when Jews, Christians, and Muslims were still living, mostly peacefully, next to each other in societies with a high degree of religious and linguistic diversity. Consequently, the project used a comparative approach to situate the Kitāb al-shifāʾ, as a biography of the prophet Muḥammad, in interdenominational discussions about false and true prophets, because Judaism, Christianity, and Islam, the three monotheistic religions, agree that prophecy is one means of divine revelation. On the other hand, the project traced the diffusion of the Kitāb al-shifāʾ in a long-term perspective, from the twelfth century to the present. The focus on the work’s reception allowed the project to refute the widely repeated claim of Islam’s essentially unchanging and unchangeable “medieval nature,” commonly adduced as the reason as to why Islam and modernity are irreconcilable, by documenting how over time Muslim readers changed their approaches to and their understanding of the Kitāb al-shifāʾ.
Scholarly Relevance. The project selected the Kitāb al-shifāʾ, because it is an important twelfth-century source for the history of the Islamic West which never dropped out of circulation. In publications on the legal and political history of Iberia and North Africa during the transition from the rule of the Almoravids (1061–1147) to that of the Almohads (1130–1269), scholars of Islam in Iberia—among others, Maribel Fierro, Cristina de la Puente, Delfina Serrano, Camilo Gómez-Rivas, and Javier Albarrán—draw on the work. To this day Malikis continue to teach the book as a work of hadith scholarship and theology (Ar.ʿilm al-kalām), and yet, it has also transcended its historical and regional origins. As documented by dated manuscript evidence, the Kitāb al-shifāʾ circulated widely in the Islamic East, outside Maliki circles, from the thirteenth century onwards, and became—in the words of Annemarie Schimmel (1922–2003), a renowned scholar of Islam on the Indian Subcontinent—“perhaps the most frequently used and commented-upon handbook in which the Prophet’s life, his qualities, and his miracles are described in every detail” (And Muḥammad is his Messenger, 1985, p. 33). Muslim publishers continually issue new printed versions, ranging from various editions of the Arabic text to translations into English, French, German, Spanish, Urdu, or Malay, while the number of digital surrogates of manuscripts and nineteenth-century printed versions available in digital depositories on the Internet is steadily increasing.
Feasibility. For some of the most important works of Islamic literature that were written in the Islamic West, just a single manuscript has been preserved. Famous examples are the only known Arabic translation (ed. ʿA. al-Badawī, Beirut, 1982; and ed. M. Penelas, Madrid, 2001) of the Latin universal history Historiae adversum paganos (“History against the pagans”) by the Christian historian Orosius (active early 5th century); the love story of Bayāḍ and Riyāḍ (ed. A. d’Ottone, Vatican City, 2013); and the Ṭawq al-ḥamāma (“The ring of the dove”), a treatise on love by the philosopher Ibn Ḥazm (994–1064; cf. J. J. Witkam, “Establishing the stemma,” Manuscripts of the Middle East 3, 1988, pp. 88–101). In contrast, hundreds of Kitāb al-shifāʾ manuscripts are preserved in accessible collections worldwide. The rich manuscript tradition offers the invaluable opportunity to study the Kitāb al-shifāʾ’s diffusion in a long-term perspective.
State of the Art. The Kitāb al-shifāʾ’s enduring popularity with Muslim readers from the thirteenth century onwards had not yet received any attention from scholars in Middle Eastern and Islamic Studies. On the one hand, popularity is often mistaken as an indication that a literary work has already been comprehensively studied. But so far, the Kitāb al-shifāʾ has been primarily valued as a source, which seems so well-known that nothing really new or original could be said about it. On the other hand, the Kitāb al-shifāʾ is a comparatively late addition to the already substantial corpus of literature about the prophet’s life (Ar. sīra), of which the oldest known works were compiled in the late seventh century. Even though Middle East historians are nowadays firmly committed to overcoming the Orientalist paradigm according to which “the West” generated knowledge about “the East” in order to perpetuate its global economic and political power, the contemporary western discourse on Islam and Muslim societies has remained anchored to the premise that the intellectual decline of the Islamic civilization from the thirteenth century onwards is one of the root causes for the undeniable socio-economic and political problems of twenty-first century Muslim societies in Eurasia and Africa. The negative view of the Islamic civilization between the thirteenth and nineteenth centuries has ensured that these centuries are perceived as a middling period and attract fewer scholars so that much less is known about them.
Objective. Taking as a starting point the observation that the Kitāb al-shifāʾ is effectively invisible in scholarship as a work in its own right, the project adopted a change of perspective. The work’s rich manuscript tradition was approached as a hitherto neglected opportunity to review established notions about the work and its author. On its most general level, the project is designed as a proof-of-concept study. Its main objective was to demonstrate that even for a well-known work like the Kitāb al-shifāʾ examining accessible manuscripts will generate fresh insights which, in turn, significantly advance our understanding of the intellectual and cultural history of the Islamic civilization, since they challenge, and often outright refute, received opinion. In addition, the project highlights that manuscripts of popular works in accessible collections in Europe and North America are an underused “hidden” resource with great research potential.
Methodological Contributions. The project’s methodological approach was based on the hermeneutic principle that historical facts about a work’s origins cannot be deduced from historical evidence for its later circulation, as composition and reception are different stages in a work’s life cycle. But historical facts about a work’s circulation can, in a second step, support conjectures about its origins, thereby opening new avenues for further research. With regard to the Kitāb al-shifāʾ, the project confronted two diametrically opposed challenges: on the one hand, the complete lack of internal or external evidence for the concrete circumstances in which Qāḍī ʿIyāḍ wrote the Kitāb al-shifāʾ in the first half of the twelfth century, and, on the other hand, a rich manuscript tradition for the book’s diffusion from the thirteenth century onwards. In order to address both challenges simultaneously, the project combined the methodologies of manuscript studies with those from the Digital Humanities. New concrete facts for the Kitāb al-shifāʾ’s diffusion were gleaned through the hands-on examination of its manuscripts, in particular dates and places for the production of manuscripts, or proper names and places for owners or readers. With the help of a cataloguing template and a Data Management Plan (DMP), these diverse historical facts were systematically recorded as “data” so that they can be preserved in online repositories for future reuse (e.g., computational semantic analysis).
Historical Contributions. The project has yielded surprising new insights into the evolution of pious literature, reading practice, and religious education in connection with the veneration of the prophet Muḥammad from the twelfth-century onwards. The diffusion of the Kitāb al-shifāʾ was plurilinear, since the work could accommodate orthodox Maliki as well as more fluid Sufi readings. In other words, the general Sunni reverence for the Kitāb al-shifāʾ, which is so richly documented from the fifteenth century onwards, was independent from the work’s Maliki origins in the Islamic West. But the recent attention paid to possible connections between the Kitāb al-shifāʾ and Qāḍī ʿIyāḍ’s tenure as a judge in Granada—the city which thanks to the Alhambra is perhaps most vividly associated with the flowering of the Islamic civilization in Iberia—marks a new stage in the work’s reception, as it reflects the active appropriation of “al-Andalus” as a central site of communal memory for Muslims in Europe and North America in the twenty-first century.
Work and Dissemination. The Experienced Researcher (ER) and her sponsor worked on the project. In consultation with the Digital.CSIC, the ER wrote a cataloguing template and a DMP to organize and standardize the manuscript descriptions for a future online database, which will supplement the project’s publications about the Kitāb al-shifāʾ and can be analyzed with computational tools (e.g., mapping, visualization). In collaboration with a colleague from the Universidad Complutense de Madrid, the ER organized in Madrid a two-day international workshop about the comparative study of Jewish, Christian, and Muslim literatures about prophets and saints from Iberia between 600 and 1600. They are now preparing for publication in 2020 a co-edited collective monograph with articles based on selected presentations. The ER examined Kitāb al-shifāʾ manuscripts in Spanish, German, American, Dutch, and British libraries. She participated in six conferences in Spain, Germany and the USA; in four workshops in Germany, Spain, and the Netherlands; in two seminars in the USA and in Spain; and in one panel discussion in Germany. As regards outreach and dissemination, the ER wrote about the project on her research blog, and selected posts are available in the Digital.CSIC and the Academic Commons of Columbia University (USA). She completed one article about the Kitāb al-shifāʾ in Ottoman book culture, which is in press and will be published later this year, and is currently completing two more articles; the three articles will be made available in Green Open-Access.
This project has received funding from the European Union’s Horizon
2020 research and innovation programme under grant agreement No. 706611.
Pious Reading as Spiritual Practice: A Biography of the Prophet Muḥammad from Twelfth-Century Iberia
al-Qāḍī ʿIyāḍ, Kitāb al-shifāʾ.
University of Michigan Library, Isl. MS 209, p. 640, detail.
MS arab. h = 21 cm, dated 1269/1852
Individual or communal reading of revelation and other sacred literature is a spiritual practice across faith traditions in literate societies. The Kitāb al-shifāʾ bi-taʿrīf huqūq al-Muṣṭafā (“The book of healing concerning the recognition of the true facts about the Chosen One”) has been a bestseller of devotional literature with Muslim audiences for centuries, all over the world. Its author ʿIyād b. Mūsā (1083–1149) was an important Maliki jurist who spent most of his professional life as a judge (qāḍī) in Ceuta. A loyal partisan of the Almoravid dynasty (1040–1147), Qāḍī ʿIyāḍ died in exile in Marrakesh, and became one of the saints of the city. Drawing on the evidence of manuscripts and printed versions, this lecture will use the Shifāʾ to explore different modes of pious reading in Muslim societies since the twelfth century.
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 706611.